Well Order Optimization¶
In this section we introduce the reader to preparing, launching and analyzing results of an optimization of well order in a drilling sequence for several planned wells. First, we formulate an example optimization problem and we explain the configuration files. Next, we show how to launch an optimization experiment and then we analyze the results:
Define optimization problem¶
We are interested in finding drilling sequence of several wells that maximizes a certain objective function over a certain set of geological scenarios and over a certain time period.
Optimization variables¶
Drilling priority values¶
We plan to drill 6 wells; 4 producers: A1, A2, A3, A4 and 2 injectors A5, A6. We choose the starting date for drilling to be 2022-09-03. We assume that the drilling rig continuously available without any interruptions. We also assume that it takes 120 days for each well to be drilled, completed and ready to operate. This means that the dates at which wells will be opened in the model are fixed and we only search for optimal opening order. See the Table: Initial drilling order for resulting drilling dates based on chosen starting date and drilling times.
Dates |
2023-01-01 |
2023-05-02 |
2023-08-31 |
2023-12-30 |
2024-04-29 |
2024-08-28 |
Wells |
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
Priorities |
0.6 |
0.55 |
0.5 |
0.45 |
0.4 |
0.35 |
Let’s assume, we want to start optimization with wells drilled in alphabetical order. We need to assign drilling priority value for each well. The higher the probability value the earlier the well will be drilled. This means, we need to choose the highest priority value for the first well (A1) and lowest priority for the last well (A6). See the Table: Initial drilling order for chosen well priority values. We recommend spacing priority values evenly. We also need to specify what standard deviation to use when randomizing priorities for perturbations. We recommend setting standard deviation to be equal to difference between the priority values (0.05 for the example in Table: Initial drilling order). For information on how to define a more complex time scheduling constraints with rig and slot availability, see relevant documentation section (EVEREST documentation)
Objective functions¶
Net present value (NPV)¶
A single objective function is utilized in this well trajectory optimization tutorial. The economic objective function is defined as Net Present Value (NPV) as follows:
Where \(q_{o,k}\) is the oil production rate in \(\frac{Sm^3}{day}\), \(q_{g,k}\) is the gas production rate in \(\frac{Sm^3}{day}\), \(q_{wp,k}\) is the water production rate in \(\frac{Sm^3}{day}\), \(q_{wi,k}\) is the water injection rate in \(\frac{Sm^3}{day}\), \(r_o\) is the price of oil in \(\frac{$}{Sm^3}\), \(r_{wp}\) is the cost of water produced in \(\frac{$}{Sm^3}\), \(r_{wi}\) is the cost of water injected in \(\frac{$}{Sm^3}\), \({\Delta}t_k\) is the difference between consecutive time steps in days, \(c_k\) are the CAPEX costs, \(b\) is the discount factor expressed as a fraction per year, \(t_k\) is the cumulative time in days corresponding to time step \(k\), and \({\tau}_t\) is the reference time period for discounting, typically one year (365.24 days). The unit prices for oil production (\(r_o\)), gas production (\(r_g\)), water production (\(r_{wp}\)), and water injection (\(r_{wi}\)) as well as drilling costs can be defined in well_order/everest/input/prices.yml.
Simulation models¶
Drogon Reservoir Model¶
The Equinor Drogon model is a synthetic reservoir model designed for testing and demonstrating ensemble-based workflows, including uncertainty quantification and optimization in subsurface projects. It is publicly available on GitHub to facilitate reproducible research and training.
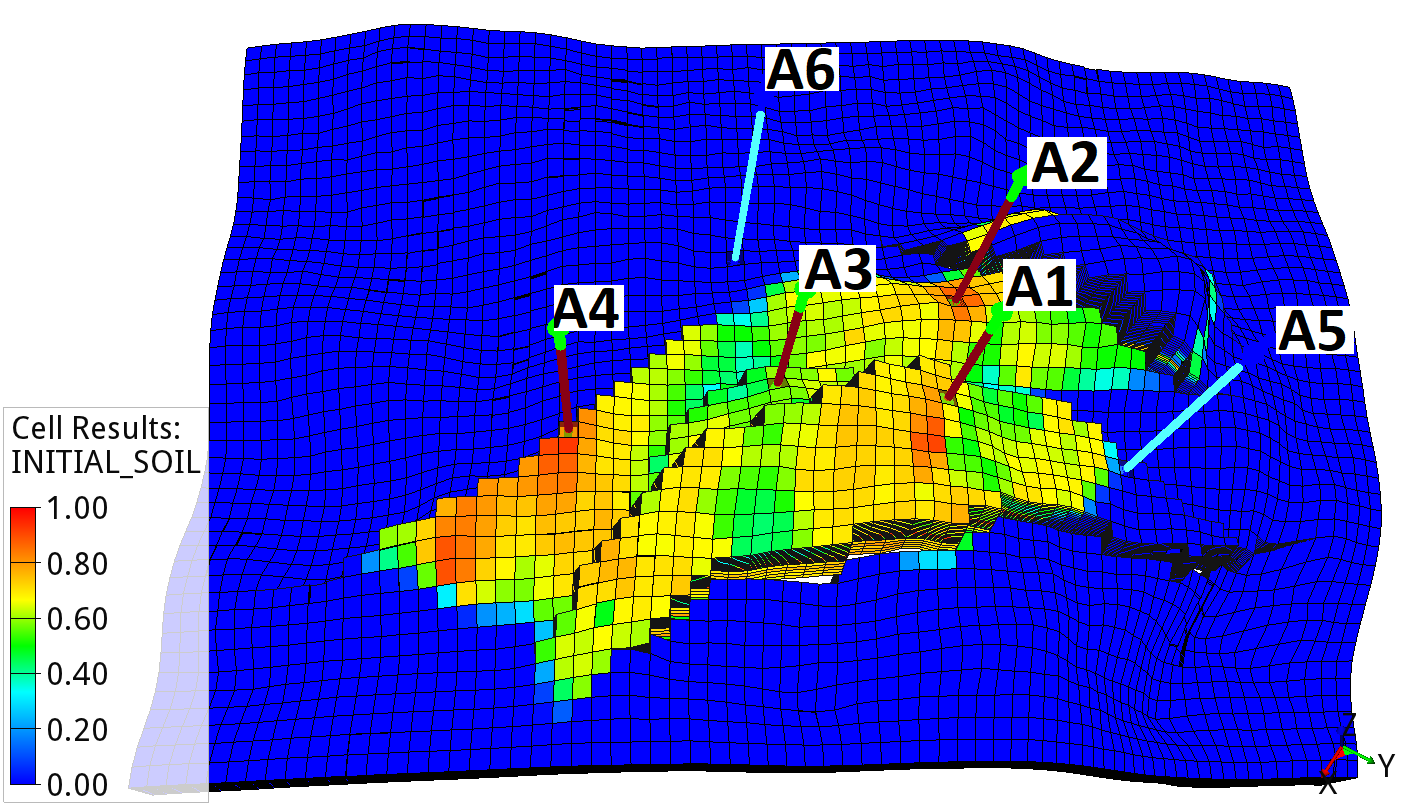
Drogon model: Average initial oil saturation across the ensemble.¶
The model contains four production wells (A1 to A4) and two water injection wells (A5 to A6). In this tutorial, the production and injection starts in September 2022 and is simulated until January 2030. The average oil saturation across the 100 geological realizations for September 2022 is shown in Drogon model: Average initial oil saturation across the ensemble.. The production wells A1 to A4 are located within the oil-bearing zone, while the injection wells A5 and A6 are placed below oil-water contact.
Prepare configuration¶
The downloaded material is already complete and ready to be launched, however it is still useful to understand how the defined problem was configured. Information related to initial guess, objective functions and the model needs to be specified in main EVEREST configuration file. After downloading tutorial files from Download Material this file will be located at well_order/everest/model/wellorder_experiment.yml.
Main configuration¶
The initial guess for EVEREST is located in the section controls in main configuration file. This is where we insert the initial priority values for each well:
controls:
- name: well_order
min: 0
max: 1
perturbation_magnitude: 0.05
variables:
- {name: A1, initial_guess: 0.6}
- {name: A2, initial_guess: 0.55}
- {name: A3, initial_guess: 0.5}
- {name: A4, initial_guess: 0.45}
- {name: A5, initial_guess: 0.4}
- {name: A6, initial_guess: 0.35}
At every iteration EVEREST will randomly perturb current best priority values and use this information to calculate the direction and step size to propose improved priority values (and therefore improved drilling order) for the next iteration. This means that we need to choose the size of the perturbation, see standard deviation input as perturbation_magnitude in the controls section. We also need to choose number of perturbations for each geological realization, see keyword perturbation_num in optimization section:
min_realizations_success: 50
options:
We also need to specify the name of the objective function in the objective_functions section. EVEREST will require file of the same name generated by one of the forward model jobs.
- name: npv
Configuration of forward jobs¶
For every set of priorities EVEREST needs to translate these priorities into drilling schedule, and then insert selected keyword template responsible for opening the well into simulation schedule file at the correct date. This is accomplished by a sequence of forward jobs, i.e.:
- drill_planner -i wells.json -c input/drill_planner_config.yml -opt well_order.json -o wells.json
- add_templates -i wells.json -c input/template_config.yml -o wells.json
- schmerge -i wells.json -s simulator/model/WELLORDER.SCH -o simulator/model/SCHEDULE_OPT.SCH
- job: flow r{{eclbase}} --enable-tuning=true
results:
file_name: r{{eclbase}}
type: summary
- npv -s r{{eclbase}}.UNSMRY -o npv -c input/prices.yml -i wells.json -sd 2023-01-01 -ed 2030-01-01
The drill_planner job will translate a set of priorities given by EVEREST into a drilling schedule, i.e. each well will be assigned a date according to drilling order at which to insert a keyword template. The start date and rig availability needs to be specified in the input file to the drill planner, i.e. well_order/everest/input/drill_planner_config.yaml:
start_date: 2022-09-03
end_date: 2030-01-01
rigs:
- name: 'A'
wells: ['A1', 'A2', 'A3', 'A4', 'A5', 'A6']
The add_templates job will assign a keyword template for each well. In case of drilling order optimization this template contains simulator specific keyword to open the well:
WELOPEN
'{{ name }}' 'OPEN' /
/
where EVEREST will replace {{name}} with the name of the well. Finally the schmerge (schedule merge) forward job will take the input schedule template WELLORDER.SCH and insert the WELOPEN keyword for each well and the correct date. Then it will produce updated schedule file SCHEDULE_OPT.SCH which will be used by the reservoir simulator. The remaining two forward jobs:
results:
file_name: r{{eclbase}}
type: summary
- npv -s r{{eclbase}}.UNSMRY -o npv -c input/prices.yml -i wells.json -sd 2023-01-01 -ed 2030-01-01
are responsible for launching reservoir simulator and calculating NPV. The NPV input file well_order/everest/input/prices.yml contains economic input parameters such as unit prices for oil production, water production and injection, drilling costs, discount factor, etc. For more detailed information and examples regarding the forward models please refer to the EVEREST Documentation.
Simulation schedule template¶
Before the optimization, the schedule file for simulation needs to be adapted. For example, in case of optimization of drilling order, EVEREST will insert WELOPEN keyword for optimized wells. Therefore, if a different well order was defined in the schedule it needs to be removed. At the same time, wells need to have specified well controls in the beginning of the schedule with keywords such as WCONPROD or WCONINJE but the optimized wells need to have there SHUT status. See an example schedule template in downloaded material: well_order/simulator/wELLORDER.SCH. The updated schedule file by EVEREST can be seen in the simulation output directory defined in main EVEREST configuration file:
environment:
simulation_folder: r{{configpath}}/../output/r{{case_name}}/simulation_output
Updated schedule files for two different perturbations can be open to see the differences.
Run EVEREST and analyze results¶
After downloading the tutorial files from Download Material and the reservoir model realizations from Drogon Reservoir Model we need to point EVEREST to the downloaded model realizations by changing the line:
definitions:
realization_folder: r{{configpath}}/../../../fmu-drogon-flow-files/realization-r{{realization}}/iter-0/eclipse
to the correct directory path.
Note
In addition we might want to change the name of the cluster scheduler. If no cluster support is present, then we can change the line to run all simulations locally, i.e., change lsf to local in line:
queue_system:
name: lsf
See also EVEREST documentation.
To launch EVEREST, we can execute the following command in the directory with configuration file:
everest run wellorder_experiment.yml
Note
The string r{{configpath}} will be interpreted as a directory path to the configuration file and the string r{{realization}} will be interpreted as integer number of the geological realization.
Note
For more information on command line interface of EVEREST type everest --help
Attention
Note that the optimization results may differ when launched on a different machine, python version or random seed due to random perturbations.
After optimization is finished we can take a look at the output directories defined in environment section of EVEREST configuration file:
environment:
simulation_folder: r{{configpath}}/../output/r{{case_name}}/simulation_output
output_folder: r{{configpath}}/../output/r{{case_name}}
In our case we can find optimization results in r{{configpath}}/../output/r{{case_name}}/optimization_output and reservoir simulation results in r{{configpath}}/../output/r{{case_name}}/simulation_output. The reservoir simulation results will be organized per batch and simulation index. This means that since we have 100 realizations, then directories which end with simulation_0 to simulation_99 represent current best drilling order and the remaining directories, i.e., simulation_100, simulation_101, simulation_102, etc. correspond to the randomly perturbed drilling order. The total number of simulations will therefore depend on the choice of number of perturbations in the main configuration file of EVEREST. In our case, we selected 1 perturbation for each geological realization therefore in total we should have 200 simulation directories at each iteration.
Note
Drilling order in batch 0 is the chosen initial drilling order.
Note
Depending on the choice of speculative option in optimization section, the calculations for current best solution and for the gradient might be split in multiple batches, see EVEREST documentation.
The Figure: Objective function over the iterations shows average objective function at the iterations of the optimization experiment (average NPV over all geological realizations). The increase in objective function value of $6.24e+07 was achieved by changing a drilling order from the initial guess.

Figure: Objective function over the iterations¶

Figure: Initial and optimal priorities¶
The drilling order is defined by set of priority values. We can compare these values for the initial guess and optimal solution, see Figure: Initial and optimal priorities. Most notably, the priority value of the producer A4 and injector A5 increased placing them in front of producers A2 and A3. In addition, the priority values of injector A6 decreased, reinforcing its place at the end of the drilling sequnce, see Table: Initial and optimal drilling order.
Dates |
2023-01-01 |
2023-05-02 |
2023-08-31 |
2023-12-30 |
2024-04-29 |
2024-08-28 |
Initial order |
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
Optimal order |
A1 |
A4 |
A5 |
A2 |
A3 |
A6 |
In order to understand why the gain in NPV is achieved we can compare production data from the reservoir simulations for initial and optimal strategies. We notice that, by drilling producer and injector earlier, we achieved increased oil production in the two time periods in the beginning and also increasing total cumulative oil production at the end of the production life-cycle, see Figure: Field Oil Production Rate and Figure: Field Oil Production Total.

Figure: Field Oil Production Rate¶

Figure: Field Oil Production Total¶
While we increased total oil production, the total gas production has been slightly decreased, see Figure: Field Gas Production Total. It was a beneficial trade-off for the NPV.

Figure: Field Gas Production Total¶
By drilling injector earlier, the cumulative values for water production and water injection increased compared to intitial strategy, see Figure: Field Water Production Total and Figure: Field Water Injection Total. It was again a beneficial trade-off for the NPV.

Figure: Field Water Production Total¶

Figure: Field Water Injection Total¶
This concludes the drilling order tutorial. We encourage the reader to check other types of tutorials in the Experiments section.