Architecture overview
Architecture diagrams
We are using c4model for showing architecture diagrams.
Level 1 - System Context diagram
The Context diagram is a good starting point for diagramming and documenting a software system, allowing you to step back and see the big picture. Here we draw a diagram showing the system as a box in the centre, surrounded by its users and the other systems that it interacts with.
Level 2 - Container diagram
Once you understand how your system interacts with users and external systems, a useful next step is to zoom-in to the system boundary with a Container diagram. A container is something like a server-side web application, single-page application, desktop application, mobile app, database schema, file system, etc. Essentially, a container is a separately runnable/deployable unit (e.g. a separate process space) that executes code or stores data.
The use cases and entities are the heart of our application and should have a minimal set of external library dependencies.
Level 3 - Component diagram
Next you can zoom in and decompose each container further to identify the major structural building blocks and their interactions.
The Component diagram shows how a container is made up of a number of components, what each of those components are, their responsibilities and the technology/implementation details.
Clean architecture
We follow the Clean Architecture style and structure the codebase accordingly for our API.
What is Clean Architecture?
It is a layered approach for a more civilized age.
Clean architecture aims to divide a big project into layers and pieces (classes, entities, modules etc.), and to make them independent of each other, so that our big and complex project becomes more maintainable, flexible and easy to work on together.
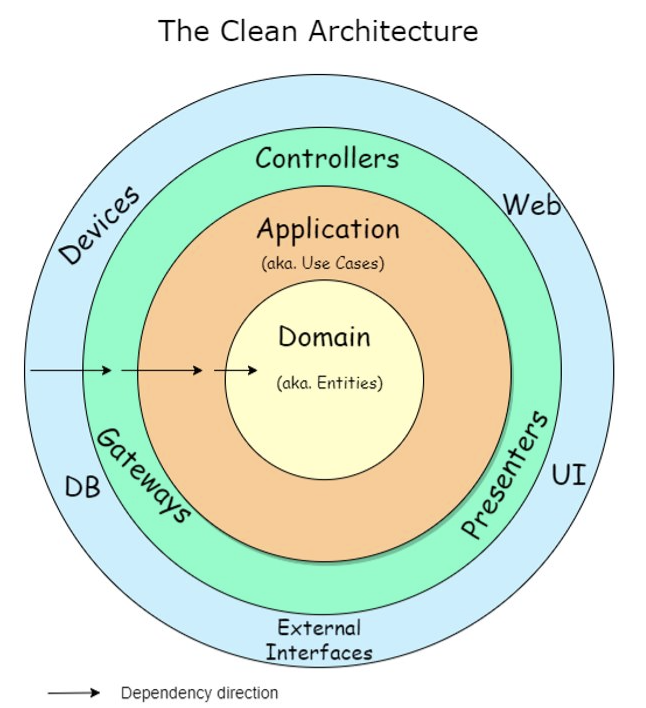
The key idea behind this diagram is that the application should be divided into layers (there can be any amount of layers). The inner layers must not know anything about the outer ones; all dependencies are directed towards the center. The further a layer is from the center, the more it knows about "non-business" details of the application (e.g. which framework is used is part of the outermost layers).
The idea to keep the core business logic (entities) and application logic (use cases) at the center of the solution structure, and independent of frameworks, databases, and external parts (the two outer layers). This allows the core part to be adaptive and flexible enough to deal with changing technology and interfaces, so that frameworks, databases, and external parts can be replaced with minimum efforts.
- The core inner entities and use cases are less likely to change
- The external layers are most likely to change based on technologies, frameworks and so on
The dependency rule
The most important rule is that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in an inner circle. That includes functions, classes. variables, or any other named software entity.
The dependency rule is the underlying rule that makes Clean Architecture work. It says that nothing in an inner circle should depend on anything in an outer circle. For example, Entities know nothing about all the other circles, while the outer layer, know everything about the inner rings. In particular, application and business rules shouldn’t depend on the UI, database, presenters, and so on. These rules allow us to build systems that are simpler to maintain, as changes in outer circles won’t impact inner ones.
The inner circle is not allowed to know anything about the outer circle.
Talk inward with simple structures (dictionaries or classes) and talk outwards through interfaces.
Why Clean Architecture?
Loose coupling- It becomes easier to modify one small piece of code without it affecting a large part of the app’s code base. This makes it easier to scale the application later on.
Testable.- It is designed so that every part of the architecture is easy testable. Our tests can be simpler to write, faster and cheaper to maintain.
Separation of concern- Different modules have specific responsibilities making it easier for modification and maintenance.
Framework independent- The architecture is framework independent. This means that it doesn’t matter which database, frameworks, UI or external services you are using - the entities and the business logic of the application will always stay the same. When any of the external parts of the system become obsolete, like the database, or the web framework, you can replace those obsolete elements with a minimum of effort.
S.O.L.I.D Principles
Single Responsibility- Each software component should have only one reason to change – one responsibility.
Open-Closed- You should be able to extend the behavior of a component, without breaking its usage, or modifying its extensions.
Liskov Substitution- If you have a class of one type, and any subclasses of that class, you should be able to represent the base class usage with the subclass, without breaking the app.
Interface Segregation- It’s better to have many smaller interfaces than a large one, to prevent a class from implementing methods that it doesn’t need.
Dependency Inversion- Components should depend on abstractions rather than concrete implementations. Also higher level modules shouldn’t depend on lower level modules.
Components
Data flow:
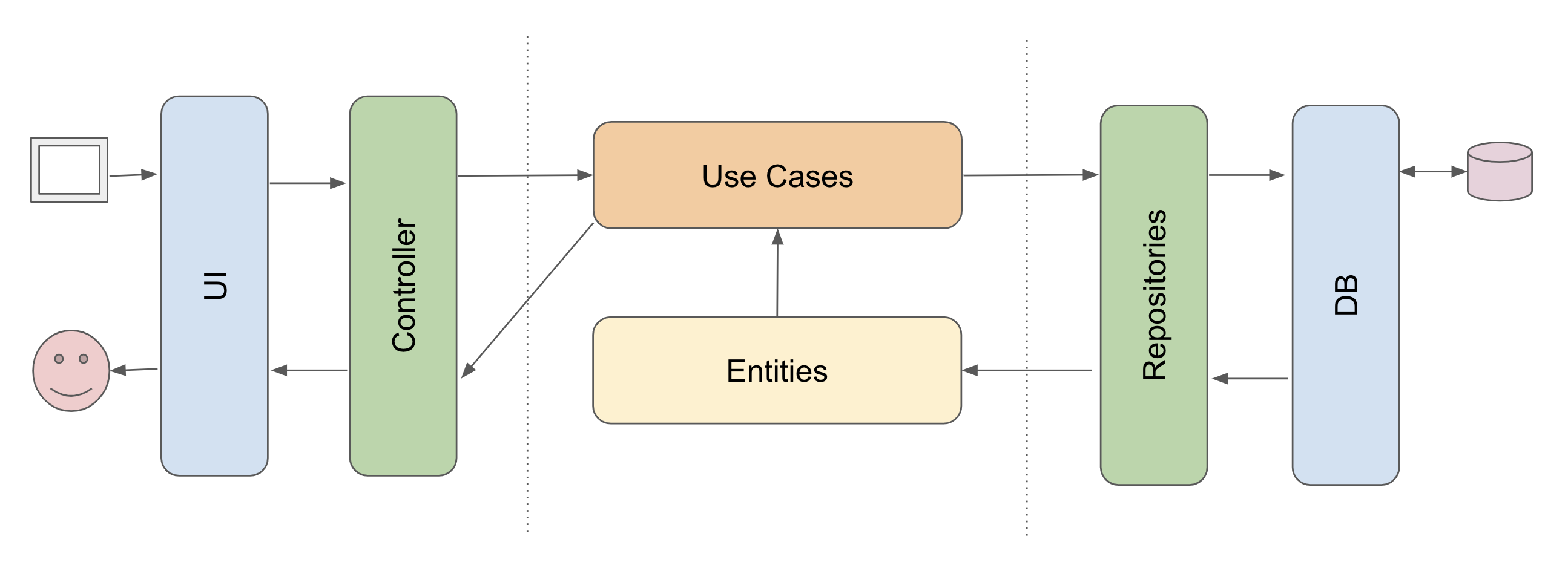
Entities- Entities are the domain model that holds data (state) and logic (business rules)
- Entities may be reused across applications in the same enterprise.
- Entities must be regular classes, dataclasses, or value objects (meaning if all the properties are the same, the objects are identical).
- Entities can not depend on anything except other entities.
- Entities should not be affected by any external change, and should be the most stable code within your application.
Use cases- Use cases are the application features (it’s what you can do with the application)
- Each use case should be limited to one feature according to the Single Responsibility Principle.
- Use cases interact with entities (thus depend on them) and hold logic of the specific application, and typically execute that logic via various repositories or data access layer(s) gateway(s).
- Use cases may define repository interfaces for the data they require, and one or more repositories will implement the repository interfaces, but the use case doesn’t know where the data is coming from.
- Use cases throw business specific exceptions.
- Use cases are not affected by changes in database or controllers.
- Use cases are the application features (it’s what you can do with the application)
Controllers- Controllers execute use cases.
- They contain no business logic, only conversion logic.
- Controllers adapt inputs from the outside world into messages the use cases can understand, and in turn adapt responses from the use cases into outputs for the world.
- You can think of them as entry and exit gates to the use cases. A controller receives a request and returns a response.
- The controller takes the user input (the request), converts it into the request object defined by the use case and passes the request objects to the use case, and at the end return the response objects.
Repositories- A repository takes entities and returns entities, hides storage details.
- Repositories implement interfaces defined by use cases.
- Could have multiple implementations, e.g. from db or from file system.
- Hides all details about where the data is from.
- Can work against local, remote, data services or third party services.
Business rules
The business logic is divided into two layers:
- The domain layer (aka entities)
- The application layer (aka use cases)
The domain layer contains the enterprise business logic, and the application layer contains the application business logic. The difference being that enterprise logic could be shared between systems whereas application logic would typically be specific to single system.